
Abkühlung, durchgängig frische Software und g33k-Bugs im Linux-Kernel
Mehr Tempo und aktuelle Software seit Monatsbeginn für alle!
Durch direkte Anbindung aller Systeme nach außen mit nun mehr als 5 TBit/s zu regionalen Carriern und Internet Exchanges weltweit, wählt jede Anfrage zum Webspace und allen anderen Diensten den jeweils kürzesten Weg aller Seitenbesuchern zu bplaced!
Alle Dienste, wie etwa der FTP- und Webserver, sowie alle Datenbanksysteme (siehe https://my.bplaced.net/datenbanken) wurden auf die jeweils aktuellste Version aufgefrischt und sogar noch ein wenig für mehr Leistung optimiert, DNS-Dienste antworten nun noch fixer auf Anfragen und Webseiten steht mehr Speicher für Caching zur Verfügung!
Aber mit nur 16 kByte RAM für unsere Server?
Ja. Denn ab und zu kam es in letzter Zeit vor, dass Webseiten etwas träge am Laden waren – die Ursache war schnell gefunden, die Suche nach dem Grund führte jedoch in unerwartete Gewässer. Dazu ist etwas Einleitung erforderlich.
Normaler weise verwaltet unser Betriebssystem, welches auf Linux basiert, den zur Verfügung stehenden Arbeitsspeicher (RAM) recht effizient. Dabei wird Speicher welcher nicht für laufende Programme benutzt wird, für andere Dinge wie etwa Caching verwendet.
Nun ist damit nicht etwa das weitgehend bekannte Caching für Webseiten oder dem Browsercache gemeint, sondern für z.B. im System geöffnete bzw. benutzte Dateien, der sogenannte Page Cache und Buffer Cache – für interessierte mit mehr Infos im Kernel-Handbuch: Kapitel 15
Die Namensgebung kann etwas verwirrend sein, unterschieden wird jedoch zwischen 2 Typen, welche den Inhalt offener Dateien oder den Index auf dem Dateisystem zu diesen, zwecks schnellerem Zugriff bei erneutem Aufruf, teils erheblich beschleunigen können. Heute wird daher nur noch zwischen dem Page Cache sowie den dentries und inodes unterschieden, auch hierzu mehr Lesestoff für besonders fleißige bei TecMint zum Thema «How to Clear RAM Memory Cache, Buffer and Swap Space».
Wenn dieser Mechanismus nicht richtig funktioniert, dann geht die G33k-Suche nach der Ursache erst so richtig los. Anleitungen wie das angeführte Leeren aller Caches (durch Ansprechen von /proc/sys/vm/drop_caches), das Abändern oder «Optimieren» der Kernelparameter via sysctl (siehe https://www.kernel.org/doc/sysctl/vm.txt), halfen erst mal keinen Schritt weiter.
Was genau passierte eigentlich?
Das ist schneller mit einem Bild erklärt, als mit so viel Fachchinesisch:
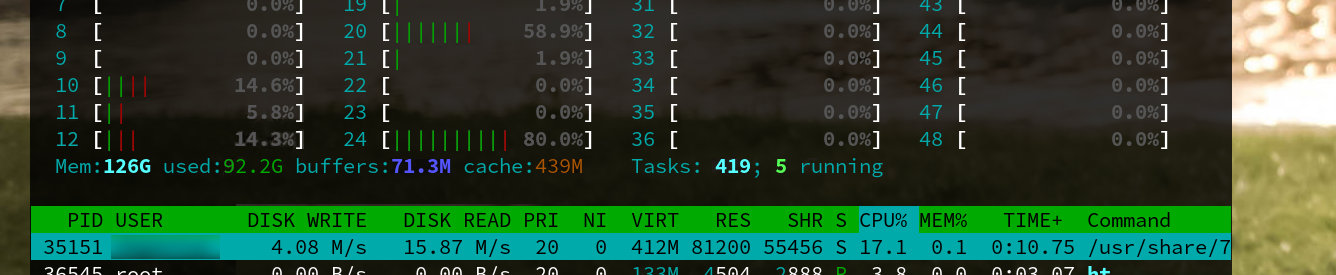
Was ist da nun zu sehen? Das System verfügt über 128 GB an RAM, wovon 92 GB in Gebrauch sind … und der Rest?
Dieser müsste nach der Theorie vorhin vollständig aufgebraucht sein, eben für Caching. Hier ist dies (zusammen mit «buffers» und «cache») nur etwa 500 MB, statt etwa rund 34 GB. Mit dem Taschenrechner durchgerechnet bedeutet dies, dass sich etwa 33 GB an RAM komplett ungenutzt auf dem Server langweilen und nicht benutzt werden, wobei dieser Cache doch dringend benötigt wird um die Reaktionszeit maßgeblich positiv zu beeinflussen.
Das ganze hat sogar einen Abwärtstrend, sodass wenige Stunden später die genannten 500 MB immer geringer werden, bis diese letztendlich irgendwann absolut nicht mehr ins Gewicht fallen und das Caching so dastehen lassen, als ob nur 16 kByte RAM zur Verfügung stünden – je nach Blockgröße ist das nämlich der Mindestwert.
Das Resultat ist, dass auf die Festplatten (egal ob alte «HDD» oder die eingesetzten SSDs über NVMe) viel häufiger zugegriffen wird und dass der Index der Dateien, welcher ja nicht zwischengespeichert ist, viel häufiger immer wieder aufgerufen werden muss – das kann letztendlich dermaßen viel Arbeit für das System bedeuten, dass dieses schlicht in die Knie geht und aus 0,1 Sekunden Ladezeit mal eben 2 Minuten werden.
Na Großartig.
Ja, genau. Deswegen ging also mal die Suche und das angesprochene «Optimieren» los. Schnell war ausgemacht, dass die Last der Festplatten ungewöhnlich hoch ist. Da kam zuerst der Verdacht auf, dass das für die Datenspiegelung benutzte RAID eventuell ganz verkehrt herum konfiguriert ist. Denn ein konkreter Verursacher wie etwa ein Programm oder ein PHP-Script, war schlichtweg nicht auszumachen. Eine schnelle Änderung der relevanten Parameter, wie beispielsweise der «stripe size», kam jedoch ohne umfangreiches Umschaufeln aller Daten nicht so einfach in Frage. Diese Größe beeinflusst die Segmente auf dem RAID-Verbund der Festplatten, oftmals auch block size bei einzelnen Festplatten genannt – mehr dazu auf Tom’s Hardware, RAID Scaling Charts, Part 3: 4-128 kB Stripes Compared. Nach einigen Experimenten auf einem Testsystem, das extra für diesen Zweck eingerichtet wurde zeigte auch, dass jegliche Änderungen beim RAID zu keiner Abhilfe führten.
Der nächste Versuch war also beim Feintuning des Kernels, genauer bei /proc/sys/vm, also bei den Parametern, welche das Verhalten des Cachings bestimmen. Da wir Swap (auch bekannt als Auslagerungsdatei) auf Grund eigentlich ausreichender Menge an RAM oftmals gar nicht verwenden und dies auch kernelseitig ausschließen wollten, gingen die ersten Tests mit Werten wie den folgenden los:
vm.dirty_ratio = 15 vm.dirty_background_ratio = 3 vm.vfs_cache_pressure = 1 vm.swappiness = 0
Diese und viele andere regelrecht durchprobierte Kombinationen mit zahlreichen weiteren Parametern, welche die Priorität und das Nutzungsverhältnis des Caching-Algorithmus bestimmen, schienen zuerst Wirkung zu zeigen und zu helfen – im Endeffekt war die Vorfreude jedoch nur falscher Alarm, zumal das unerträgliche an dieser Sache bislang noch komplett unerwähnt blieb:
Yeah, Problem gelöst! ..für die ersten 2 Wochen.
Denn das intern bei bplaced im Team noch liebevoll getaufte RAM-Problem war so dermaßen dreist, dass für eine gewisse Zeit lang durch die Optimierungen alles prima zu funktionieren schien. Ab und zu kam es allerdings sogar schon nach 3 Tagen wieder zum gleichen Verhalten, meistens jedoch nach so um die 2 Wochen. Die ganze Vorfreude war also umsonst, das Problem war nicht gelöst. Wirklich dreist (genauer genommen eher «nervig») war die Sache jedoch deswegen, weil die Auswirkungen jeglicher Änderungen und gehoffter Optimierungen nicht sofort zu sehen waren. Manche Server liefen sogar monatelang problemlos durch, während andere innerhalb der Zeit aufgrund dessen mehrfach von langer Ladezeit betroffen waren. Es war zum verzweifeln.
Nach tagelangem Herumprobieren half weder das Neustarten aller Dienste, noch das Beenden aller Prozesse, sondern nur ein Neustart des ganzen Systems. Aber warum? So etwas ist man gerade bei Linux nicht gewohnt – wir wissen jedoch vermutlich alle bei welchem System dies die Universallösung für viele Problem ist.
Wie dann zufällig rauskam, konnte das Problem durch das Aushängen der Festplatten vom System (etwas was auch beim Neustart passiert) scheinbar gelöst werden – zumindest für die nächsten 3-Tage-2-Wochen-X-Monate. So also mussten erst mal alle Dienste (wie z.B. Webserver, FTP-Server, usw.) beendet werden und mit dem umount-Befehl die jeweilig betroffenen Festplatten ausgehängt werden. Anschließend konnten die Dienste wieder neu gestartet werden und die RAM-Auslastung war für einige Zeit lang wieder insofern korrekt, als dass beim zuerst genannten Beispiel alle übrigen 34 GB für das Caching benutzt wurden.
An den Rat der Grauen Eminenzen!
Hier musste also mal eine «zweite Meinung» her, da wandten wir uns an die Kernel-Entwickler, welche die so wichtigen Details wie das Speichermanagement entwickeln und pflegen. Üblicher weise sind dies sogar professionelle Entwickler, welche bei namhaften Unternehmen, wie SuSE oder Intel fest angestellt sind. Offenbar kannte man das Problem dort nicht, sodass erst mal monatelanges Debugging mit vielen Details uns GB-weise Logs gefragt war bis klargestellt wurde, dass es sich hierbei offenbar um einen neu entdeckten Bug handelt.
Gratulation an die Technikfreaks bei bplaced, nicht jeder findet mal eben derart schwerwiegende Fehler bei solch elementaren Funktionen von so häufig verwendeter Software. Aber wieso fiel das sonst niemandem auf? Immerhin hat die Geschichte derart viele Unannehmlichkeiten verursacht, sodass man auf eine solche Entdeckung wirklich nicht hat stolz sein können.
Offenbar führte unsere komplexe Konstellation für das Webhosting zu Szenarien, die beim Testen neuer Linux-Kernel einfach nicht auffielen. Denn im Kernel 3.x bestand das Problem nicht, es kam erst ab 4.0 bis etwa 4.3 vor und damit zu selten. Denn die meisten Betreiber setzen meist ältere (und teils zu alte) Versionen ein – derart neue Software wurde nur selten unter diesen Bedingungen verwendet. Es häuften sich später auch Berichte, dass das Problem nach unserer Entdeckung bei anderen auftrat, jedoch wirbelte all dies nicht so viel Staub auf, da ein Neustart zu einer zeitweisen Lösung führte.
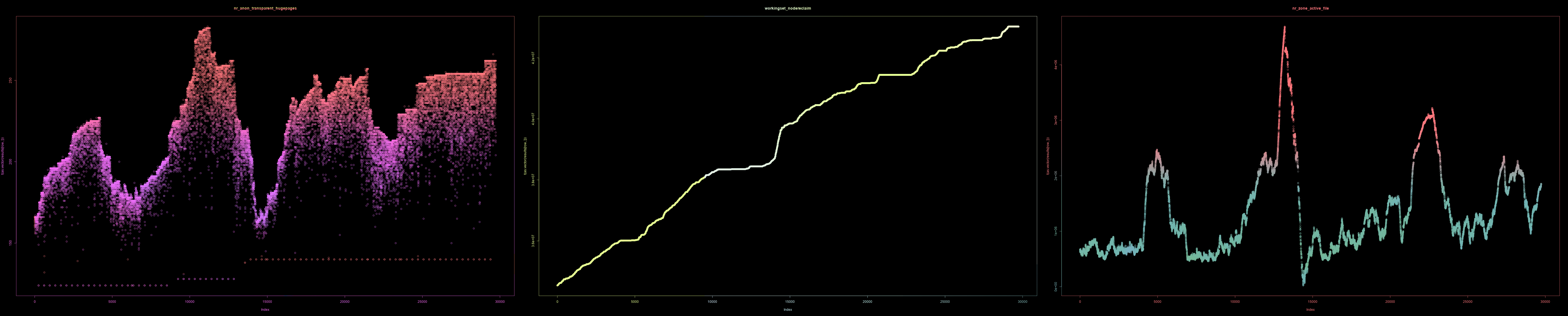
Nun ist an diesen Statistiken, welche bis zum sporadischen Auftreten über mehrere Tage angesammelt wurden zu sehen, dass die reguläre Nutzung des Caches plötzlich nachlässt und sich manchmal jedoch wieder von selbst, wenn auch nur teilweise, bessert. Die Problemursache war schlichtweg, dass ein mal zugewiesener RAM nicht erneut freigegeben wurde, wenn es zu einem gewissen Grad an Fragmentierung kam. Genauer gesagt wurde zwar der Speicherplatz anscheinend freigegeben, die sogenannten «Pages» jedoch nicht – sodass das System früher mal benutzte Speicheradressen nicht erneut verwenden konnte, da sie fälschlicher weise im Glauben genutzt zu werden, reserviert waren. Also wie ein überbuchtes Flugzeug, ohne Passagiere, über die jedoch nicht bekannt ist, wer anwesend ist und wer nicht.
Nach nun monatelanger Diagnose, viel zu viel Kaffee und zahlreichen schlaflosen Nächten, hat es letztendlich der Patch unter https://lore.kernel.org/linux-mm/2018 1126143503.GO 23260@techsingularity.net/ in den Kernel geschafft! Damit werden die Speicherbereiche wieder korrekt freigegeben und Caching kann wieder wie gewohnt zur Geltung kommen.
Besten Dank an das gesamte Team des Memory-Management, besonders an Vlastimil Babka, Michal Hocko, Mel Gorman, Christopher Lameter, David Rientjes, Andrea Arcangeli, Andrew Morton und Zi Yan – schon wenige Monate später war der Fix im aktuellen Linux 5 zu finden, welchen wir seitdem ohne jegliche Probleme mit allen Neuerungen und Features tagtäglich durchgehend auf allen Systemen im Einsatz haben 🙂




